
Why ASRS Selection Keeps Failing — and What Actually Fixes It
The Simulated Frontier: How Physical AI Breaks the Automation Vicious Cycle

Warehouse automation is no longer experimental.
Over the past 10 to 15 years, logistics operations worldwide have deployed ASRS, shuttle systems, goods-to-person solutions, AMRs, sortation, robotic palletizing, and increasingly complex hybrid architectures. Automation has become a standard response to labor pressure, service-level demands, and growth.
And yet, a quiet pattern has emerged across the industry.
A significant number of end users are not satisfied with the real-world performance of their automated systems.
Not because the technology fundamentally fails — but because it rarely behaves the way it was expected to once exposed to operational reality.
A familiar pattern across automated warehouses
The story repeats with striking consistency:
A system is designed using averages, assumptions, and best-case scenarios
The solution goes live and delivers some benefits
Performance degrades under variability, peaks, or exceptions
Optimization options prove limited after commissioning
The operation becomes constrained by decisions made years earlier
At that point, there are very few levers left to pull.
The hardware is fixed.
The workflows are embedded.
The control logic is difficult to change.
And improvement becomes incremental, expensive, or risky.
Black-box systems and constrained optimization
Most modern automation platforms present themselves as configurable and flexible.
In practice, many operate as black-box systems.
Core control logic is proprietary
System behavior is only partially observable
Optimization parameters are exposed selectively
True workflow changes require vendor intervention
When performance gaps appear, the available options are often limited to:
narrow parameter tuning
paid software change requests
extended validation cycles
hardware additions framed as “capacity unlocks”
Meaningful changes to sequencing, buffering, orchestration, or recovery logic are rarely possible without significant cost and operational risk.
As a result, many operators find themselves in a difficult position:
They can see where the system struggles — but they have no safe way to test or validate alternatives.
Vendor switching is not optimization
Over time, frustration builds.
When the next automation project arises, the instinctive response is often:
“Let’s try a different vendor this time.”
But the outcome is frequently the same.
The new system solves some problems and introduces others. Throughput ceilings reappear. Congestion shifts. Flexibility proves narrower than expected. Recovery behavior remains opaque.
The industry ends up in a familiar loop:
Disappointment → vendor change → new constraints → renewed disappointment.
This is not a failure of individual vendors.
It is a structural limitation of how automation has been designed, evaluated, and delivered.
The real limitation was never the robots
For most of the past decade, automation decisions have relied on tools that were inherently limited:
simplified simulations
static throughput models
spreadsheet math
narrow pilot scenarios
vendor-specific assumptions
These approaches work for baseline sizing, but they struggle with what actually determines success:
dynamic interactions between subsystems
emergent congestion
variability in SKU mix and order profiles
human-machine interactions
fault recovery and degraded modes
peak amplification effects
In other words, they struggle with system behavior.
As Demis Hassabis has noted in a broader AI context, models can produce outputs that look plausible without being physically correct. In warehouse automation, the equivalent problem is designing systems that look sound on paper but behave unpredictably on the floor.
Once deployed, there has historically been nowhere to go.
No neutral environment to test changes.
No way to stress-test beyond production limits.
No mechanism to learn safely after go-live.
Why this is finally changing
The emergence of world models, high-fidelity simulation, and physical AI represents a genuine break from the past.
These tools are not about visualization. They are about understanding cause and effect in complex physical systems.
They enable models that can:
capture interaction, not just flow
represent variability, not just averages
test thousands of scenarios safely
quantify confidence, not just outcomes
This is the same foundation now being pursued at organizations like Google DeepMind, where world models are viewed as essential for robotics and real-world AI.
The principle is simple:
If you cannot simulate a system accurately, you do not understand it well enough to control it.
That applies just as much to warehouses as it does to autonomous vehicles or robots.
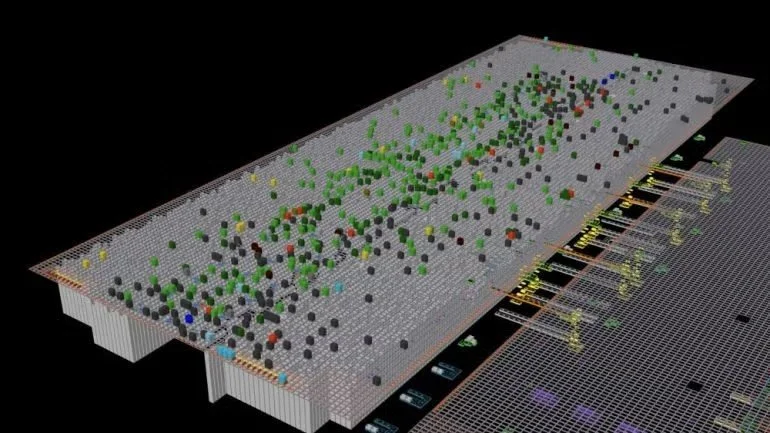
Digital twins as an escape from the automation loop
This new generation of digital twins is fundamentally different from what many operators have seen before.
They are not dashboards.
They are not static 3D replicas.
They are not vendor demos.
They are decision environments.
When built correctly, they allow teams to:
understand why a system underperforms
test alternative orchestration strategies safely
evaluate workflow changes before paying for them
separate hardware limits from control limitations
stress-test peaks, faults, and recovery paths
Most importantly, they allow optimization to continue after go-live — without putting production at risk.
Rethinking the “best ASRS” debate
Few topics generate more discussion in logistics than this question:
What is the best ASRS system available today?
Cube-based systems.
Shuttles.
Miniloads.
AMR-based storage.
Hybrid designs.
Every architecture has strengths. Every vendor has reference sites. And yet the debate never resolves — because the question itself is incomplete.
There is no universally “best” ASRS.
There are only systems that perform better or worse under specific physical and operational conditions.
Why comparisons have always fallen short
Historically, ASRS evaluations have been constrained by inconsistent assumptions:
different order profiles
different SKU distributions
different peak definitions
different recovery scenarios
Even well-intentioned third-party studies struggle with one core issue:
systems are rarely tested against the same reality.
Small changes in assumptions can completely reverse conclusions.
As a result, experience, intuition, and vendor narratives have filled the gaps.
That approach made sense when simulation fidelity was limited.
It no longer does.
Physics as the neutral referee
High-fidelity simulation enables something the industry has never truly had:
fair, third-party, physics-based comparability.
Using world models, different ASRS architectures can be evaluated against:
identical data sets
identical order streams
identical peak amplification
identical fault injection
identical service-level constraints
Each system is allowed to operate as designed — but under the same conditions.
The result is not a single “winner,” but a performance envelope:
throughput stability
sensitivity to SKU skew
congestion formation
recovery behavior
expansion headroom
long-term adaptability
This moves the discussion from ideology to evidence.
From “best system” to “best fit”
When evaluated this way, the question changes:
Not which ASRS is best?
But which ASRS behaves best for this operation, under these constraints, with these risks?
That shift matters.
It reduces regret.
It prevents over-buying.
It avoids chasing architectures that solve the wrong problem.
And it creates a repeatable decision process that improves with every project.
A starting point, not a conclusion
This article is not a rejection of existing automation technologies.
They were designed with the tools available at the time.
But the industry is reaching an inflection point.
Automation and robotics are now commonplace — yet dissatisfaction remains widespread. Not because teams made poor decisions, but because they lacked the tools to fully understand, test, and evolve complex systems.
World models, digital twins, and physical AI change that equation.
They offer a credible path to:
break the vendor-swap cycle
regain control over post-go-live optimization
evaluate systems on equal, scientific footing
make capital decisions with measurable confidence
This is the first article in a broader series exploring what this shift means for logistics and warehouse automation.
In the pieces that follow, we’ll go deeper into:
why automated systems underperform in predictable ways
how digital twins can be used before and after deployment
what vendor-agnostic evaluation looks like in practice
why orchestration, not hardware alone, defines outcomes
If you’re planning your next automation project — or living with one that isn’t delivering what you expected — now is the moment to rethink not the vendor, but the tools used to understand reality.
More to come.




























At Hannover Messe 2026, SAP and Vodafone showcased a pilot conducted at Vodafone’s warehouse in Duisburg,